1.树莓派的拷贝
建议使用树莓派官方拷贝软件:https://www.raspberrypi.com/software/
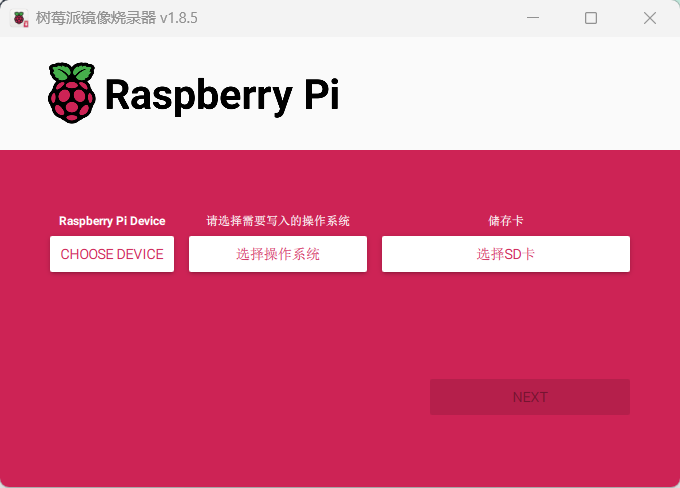
下好官方软件之后就能一步一步烧录了
相应的根据的你的树莓派型号选择,然后点NEXT
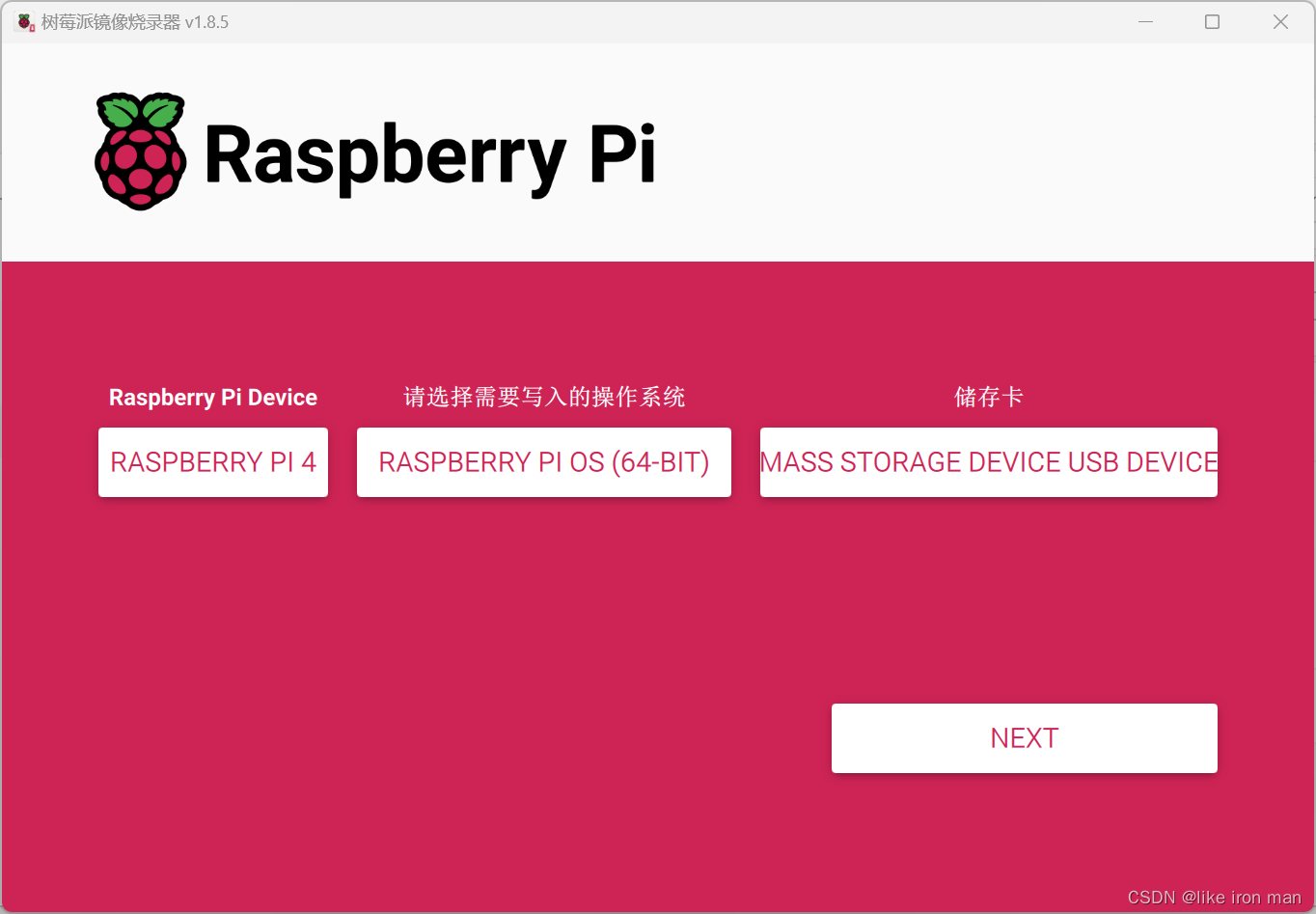
选择编译设置
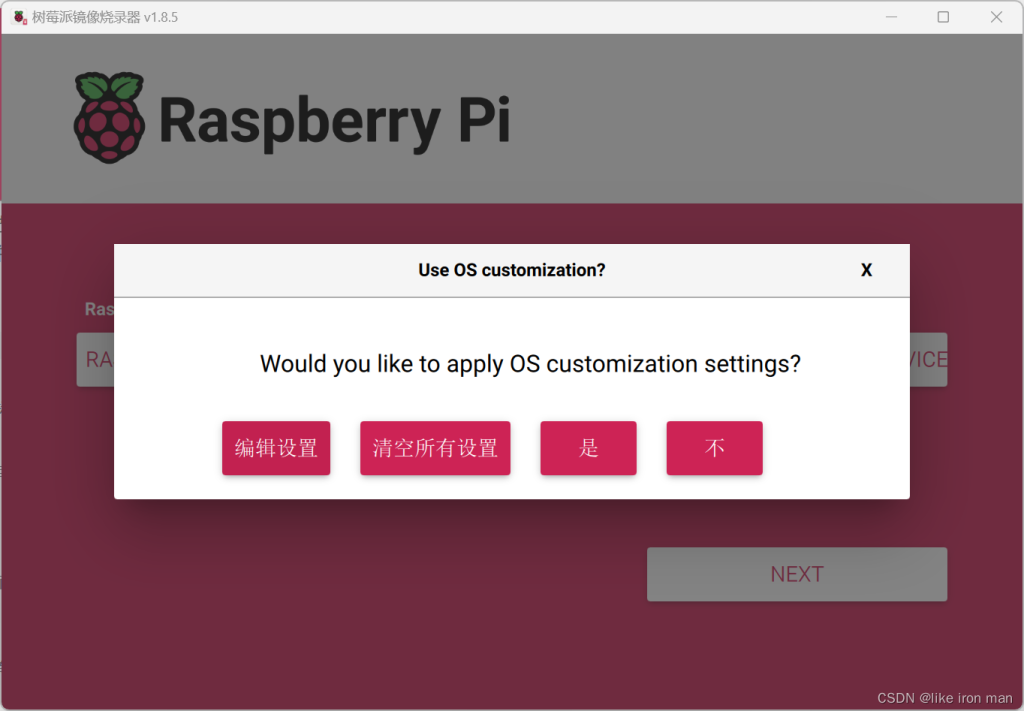
自己设置好用户名,密码,要连的热点和密码
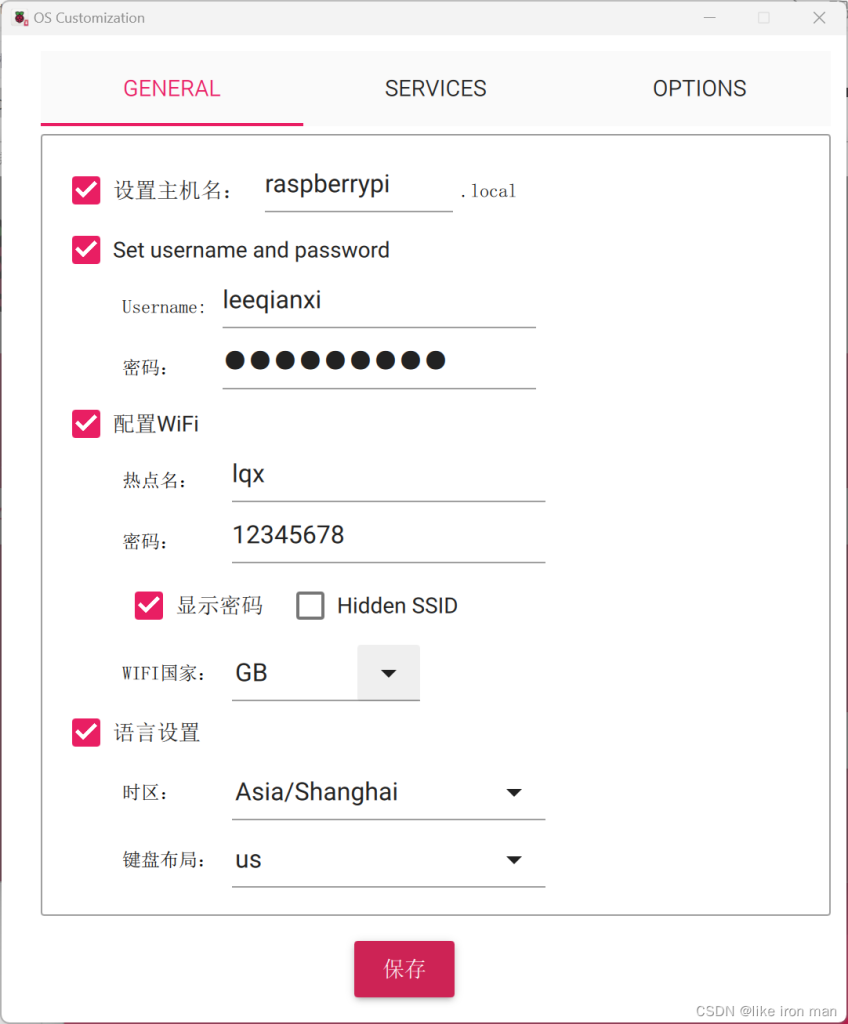
SSH协议打开要不然连接不上
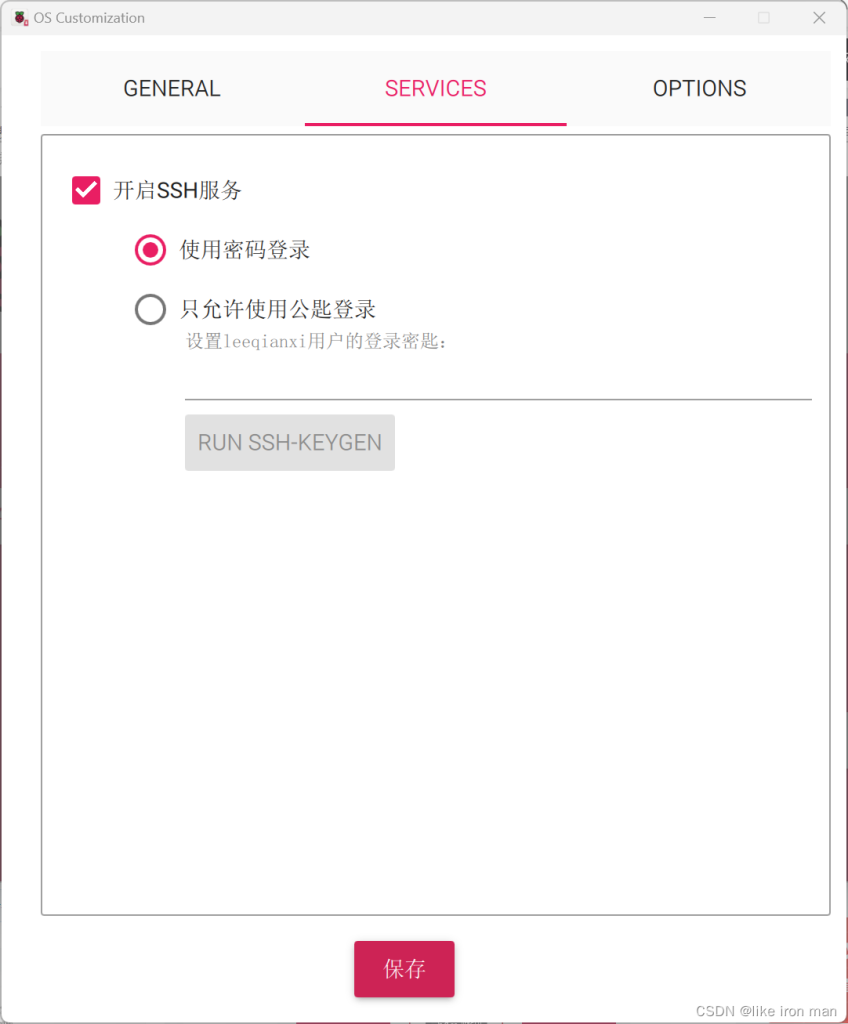
最后一个这样设置
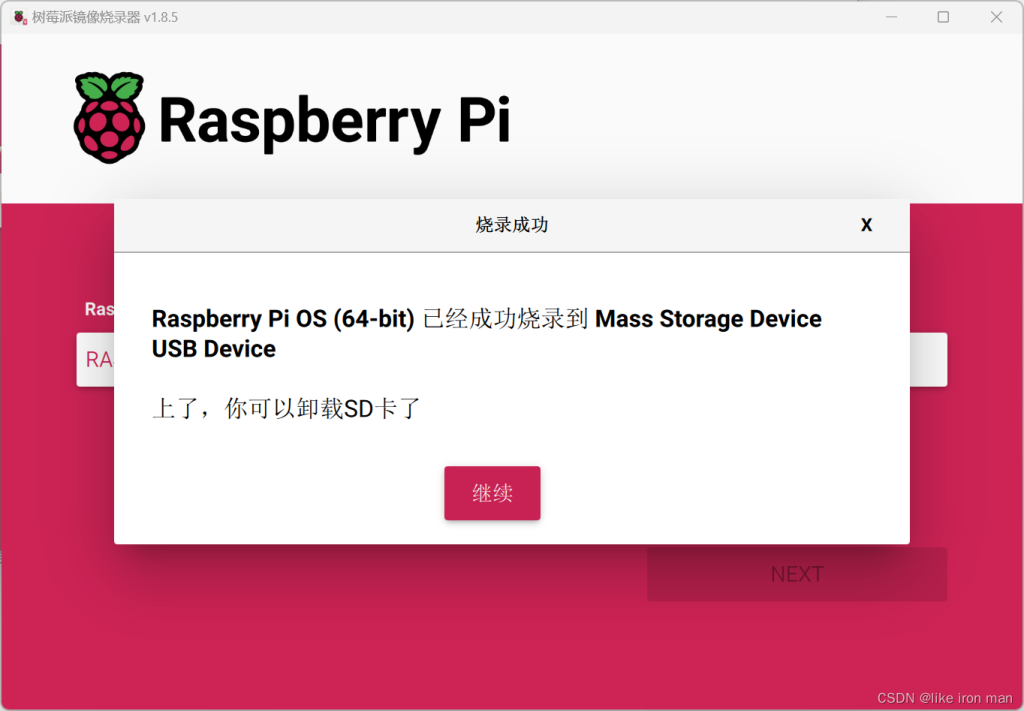
开始拷录,时间可能有点长,耐心等待。
2.树莓派的三种链接(要处在同一网络)
(1)你可以直接用终端链接:
win+R调出终端后
ssh 用户名@ip
输入密码后就能链接上
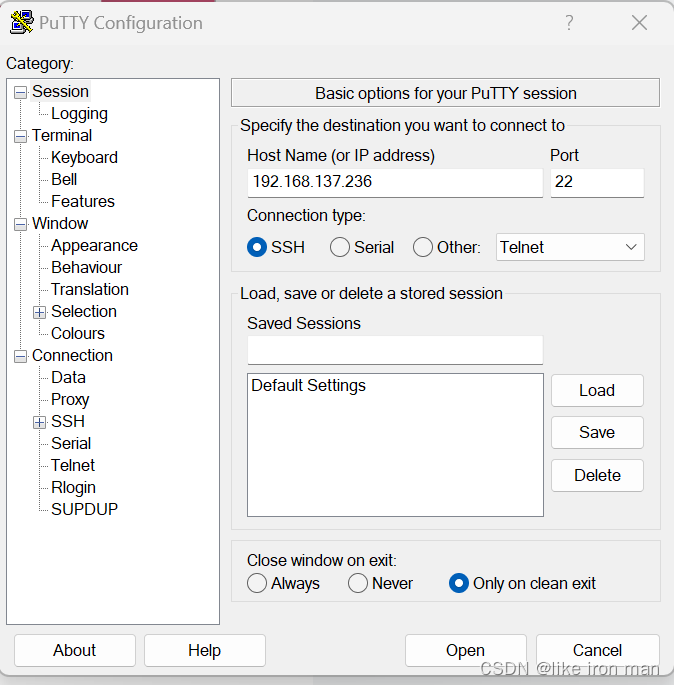
(2)用 putty连接树莓派:https://www.chiark.greenend.org.uk/~sgtatham/putty/latest.htm(putty的下载地址)
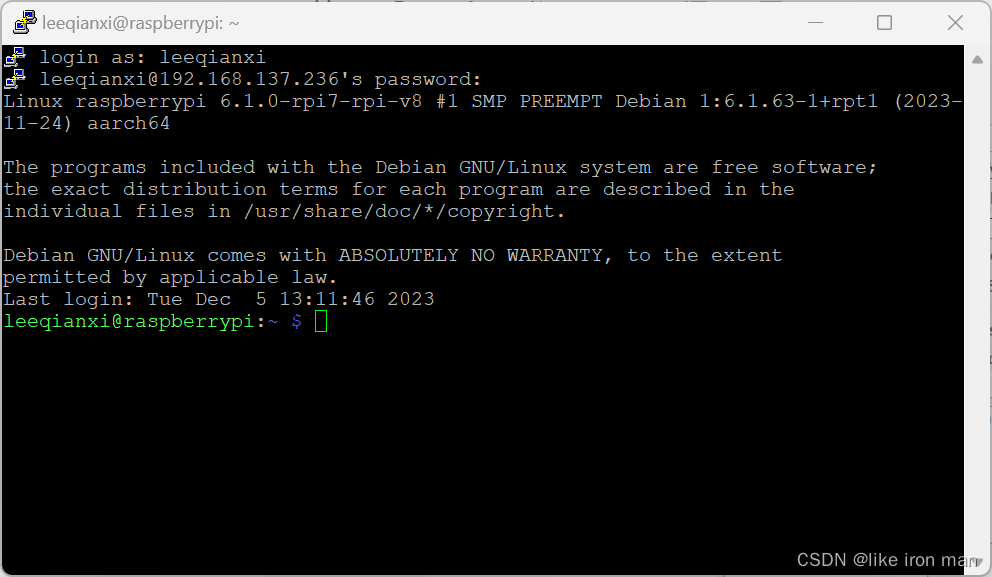
输入树莓派的IP,进入终端后,输入用户名和密码就连上了
(3)使用VNC远程桌面登录树莓派:Download VNC Viewer by RealVNC®(VNC的下载链接)
VNC的使用要开启相应的协议,得先用前两种方法连上树莓派后:
在命令行输入:sudo raspi-config,进入下面的界面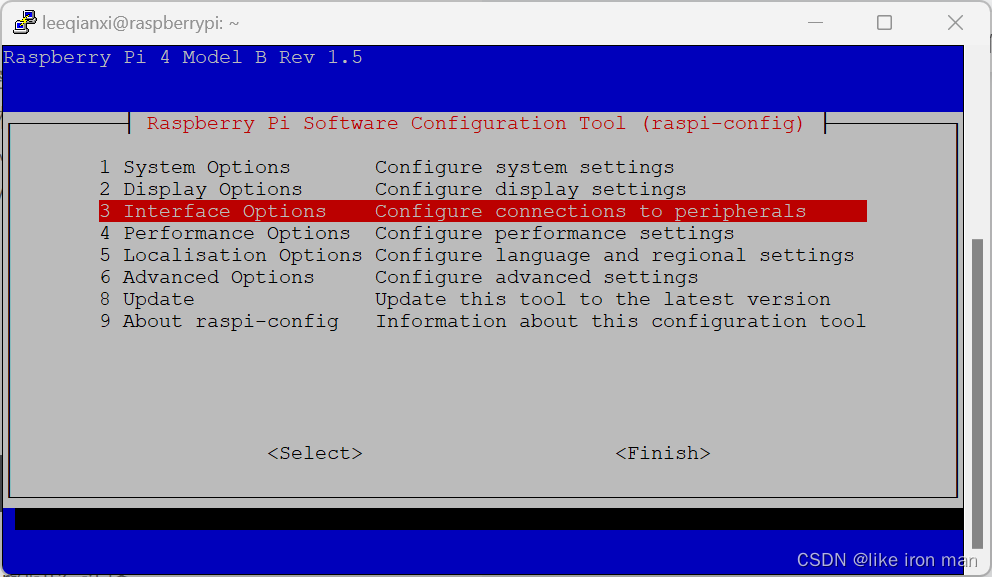
(1)打开VNC:Interfacing Options -> VNC -> Yes
(2)退出图形化界面:(左右方向键选择)Finish
完成后就能远程链接
输入IP地址
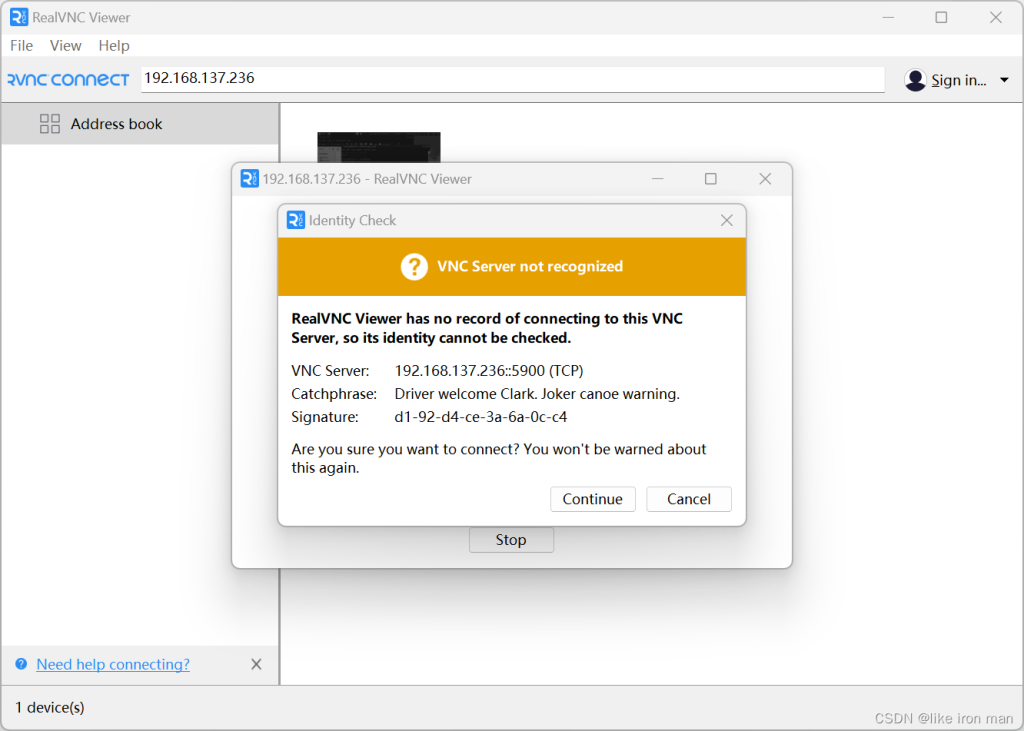
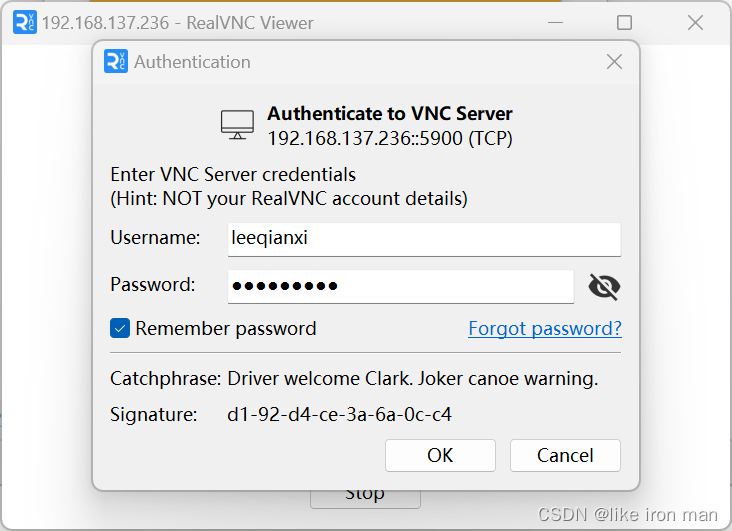
输入用户名和密码
3.人脸识别的项目
先安装opencv和相关拓展和依赖,会非常慢,建议换成清华源
sudo apt-get update && sudo apt-get upgrade
sudo apt-get install build-essential cmake pkg-config -y
sudo apt-get install libjpeg-dev libtiff5-dev libjasper-dev libpng-dev -y
sudo apt-get install libavcodec-dev libavformat-dev libswscale-dev libv4l-dev -y
sudo apt-get install libxvidcore-dev libx264-dev -y
sudo apt-get install libfontconfig1-dev libcairo2-dev -y
sudo apt-get install libgdk-pixbuf2.0-dev libpango1.0-dev -y
sudo apt-get install libgtk2.0-dev libgtk-3-dev -y
sudo apt-get install libatlas-base-dev gfortran -y
sudo apt-get install libhdf5-dev libhdf5-serial-dev libhdf5-103 -y
sudo apt-get install libqtgui4 libqtwebkit4 libqt4-test python3-pyqt5 -ypip3 install numpy(# 如果用pip3下不了可以在虚拟环境中下,或者用下面的指令强制在系统 Python 中安装
pip3 install numpy --break-system-packages
)pip3 install opencv-contrib-python==4.1.0.25(
# 如果用pip3下不了可以在虚拟环境中下,或者用下面的指令强制在系统 Python 中安装 opencv-contrib-python,绕过外部管理限制,
pip3 install opencv-contrib-python --break-system-packages)下面就可以写代码了:
1.这一部分是测试你摄像头的代码
import numpy as np
import cv2
faceCascade = cv2.CascadeClassifier('Cascades/haarcascade_frontalface_default.xml')
cap = cv2.VideoCapture(0)
cap.set(3,640) # set Width
cap.set(4,480) # set Height
while True:
ret, img = cap.read()
img = cv2.flip(img, -1)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2,
minNeighbors=5,
minSize=(20, 20)
)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
cv2.imshow('video',img)
k = cv2.waitKey(30) & 0xff
if k == 27: # press 'ESC' to quit
break
cap.release()
cv2.destroyAllWindows()其中haarcascade_frontalface_default.xml是要你从GitHub上下载一个名为“haarcascade_frontalface_default.xml”模型,放在项目文件里。链接如下: https://github.com/opencv/opencv/tree/master/data/haarcascades
(这个链接还包括眼睛鼻子等等的训练模型)
2.从多个用户中捕获多个人脸并将其存储在数据库(数据集目录)中,人脸将存储在目录:dataset/(如果不存在,请创建它),每个人脸将有一个唯一的数字ID,如1、2、3等。代码如下:
import cv2
import os
cam = cv2.VideoCapture(0)
cam.set(3, 640) # 视频的宽
cam.set(4, 480) # 视频的长
face_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 对于每个人,输入一个数字面部 ID
face_id = input('\n enter user id end press <return> ==> ')
print("\n [INFO] Initializing face capture. Look the camera and wait ...")
# 初始化个体采样面数
count = 0
while(True):
ret, img = cam.read()
img = cv2.flip(img, -1) # 垂直翻转视频图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img, (x,y), (x+w,y+h), (255,0,0), 2)
count += 1
# 将捕获的图像保存到datasets文件夹中
cv2.imwrite("dataset/User." + str(face_id) + '.' + str(count) + ".jpg", gray[y:y+h,x:x+w])
cv2.imshow('image', img)
k = cv2.waitKey(100) & 0xff # 按esc退出视频
if k == 27:
break
elif count >= 30: # 采集 30 个面部样本并停止视频
break
# 做清理
print("\n [INFO] Exiting Program and cleanup stuff")
cam.release()
cv2.destroyAllWindows()会在dataset这个文件夹里生成30张图片保存,作为一个数据图片。每张图片都会变成人脸识别部分,这里就不展示图片了。
3.必须从数据集中获取所有用户数据并“训练”OpenCV 识别器。这是由特定的 OpenCV 函数直接完成的。结果将是一个 .yml 文件,该文件将保存在“trainer/”目录中。注意确认你的 Rpi 上是否安装了 PIL 库。如果没有:pip install pillow,训练代码如下:
import cv2
import numpy as np
from PIL import Image
import os
# Path for face image database
path = 'dataset'
recognizer = cv2.face.LBPHFaceRecognizer_create()
face_detector = cv2.CascadeClassifier("haarcascade_frontalface_default.xml")
# function to get the images and label data
def getImagesAndLabels(path):
imagePaths = [os.path.join(path,f) for f in os.listdir(path)]
faceSamples=[]
ids = []
for imagePath in imagePaths:
# Load the image and convert it to grayscale
PIL_img = Image.open(imagePath).convert('L')
img_numpy = np.array(PIL_img,'uint8')
id = int(os.path.split(imagePath)[-1].split(".")[1])
faces = face_detector.detectMultiScale(img_numpy)
for (x,y,w,h) in faces:
faceSamples.append(img_numpy[y:y+h,x:x+w])
ids.append(id)
return faceSamples,ids
print ("\n [INFO] Training faces. It will take a few seconds. Wait ...")
faces,ids = getImagesAndLabels(path)
recognizer.train(faces, np.array(ids))
# Save the model into trainer/trainer.yml
if not os.path.exists('trainer'):
os.makedirs('trainer')
recognizer.write('trainer/trainer.yml')
# Print the number of faces trained and end the program
print(f"\n [INFO] {len(np.unique(ids))} faces trained. Exiting Program")4.就可以根据训练的来识别了:
import cv2
import numpy as np
import os
# 加载训练好的 LBPH 人脸识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trainer/trainer.yml')
# 加载人脸检测器
cascadePath = "haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath);
# 定义字体
font = cv2.FONT_HERSHEY_SIMPLEX
# 初始化 ID 计数器
id = 0
# ID 对应的名字,例如:Marcelo 的 ID 为 1,对应的 names 列表中的第一个元素,以此类推。
names = ['None', 'Marcelo', 'Paula', 'Ilza', 'Z', 'W']
# 初始化并启动实时视频采集
cam = cv2.VideoCapture(0)
cam.set(3, 640) # 设置视频宽度
cam.set(4, 480) # 设置视频高度
# 定义最小窗口大小以被识别为人脸
minW = 0.1*cam.get(3)
minH = 0.1*cam.get(4)
while True:
ret, img =cam.read()
# 垂直翻转视频图像
img = cv2.flip(img, -1)
img = cv2.flip(img, -1)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 使用人脸检测器检测人脸
faces = faceCascade.detectMultiScale(
gray,
scaleFactor = 1.2,
minNeighbors = 5,
minSize = (int(minW), int(minH)),
)
for(x,y,w,h) in faces:
# 在图像上绘制矩形,标记出人脸位置
cv2.rectangle(img, (x,y), (x+w,y+h), (0,255,0), 2)
# 对每个人脸进行识别
id, confidence = recognizer.predict(gray[y:y+h,x:x+w])
# 如果置信度小于100,则认为识别成功
if (confidence < 100):
id = names[id] # 获取 ID 对应的名字
confidence = " {0}%".format(round(100 - confidence))
else:
id = "unknown"
confidence = " {0}%".format(round(100 - confidence))
# 在图像上显示出识别结果
cv2.putText(img, str(id), (x+5,y-5), font, 1, (255,255,255), 2)
cv2.putText(img, str(confidence), (x+5,y+h-5), font, 1, (255,255,0), 1)
cv2.imshow('camera',img)
# 按下 ESC 键退出程序
k = cv2.waitKey(10) & 0xff
if k == 27:
break
# 清理资源
print("\n [INFO] 退出程序并清理资源")
cam.release()
cv2.destroyAllWindows()效果如下:
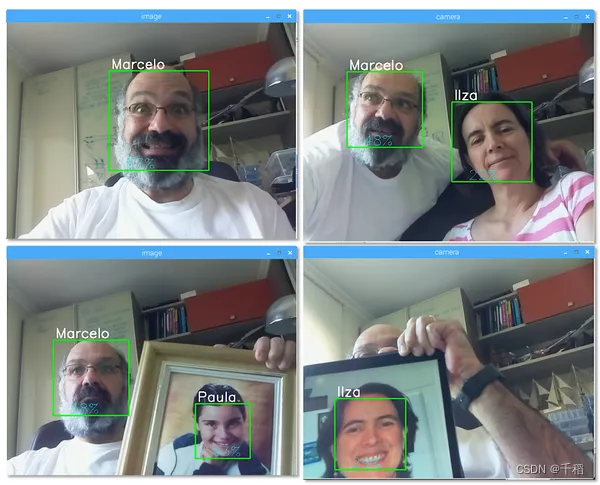
你要形成的代码结构如下:
从本地向树莓派里传输文件或文件夹的话用scp
scp 要传输的文件路径 用户名@IP:要传入树莓派的地方路径
scp -r 要传输的文件夹路径 用户名@IP:要传入树莓派的地方路径
语音部分:
sudo apt-get update sudo apt-get install espeak sudo apt-get install speech-dispatcherpip uninstall pyttsx3 pip install pyttsx3==2.71 # 尝试特定版本上面的命令可能会报错,安不了的话参考之前的虚拟环境安装或者强制安装
espeak --voices # 查看espeak可用语音根据有的语音ID写代码(建议用英文,因为最简单)
# 测试英式英语(和代码中一致)
espeak -v en-gb “Welcome, Marcelo. Warning: Unknown person detected”
相关了人脸识别和语音播报结合代码如下:
import cv2
import numpy as np
import os
import pyttsx3
# -------------------------- 1. 初始化英文语音引擎(关键:指定系统存在的英文语音) --------------------------
# 仅初始化1次,避免循环中频繁调用导致资源占用
engine = pyttsx3.init(driverName='espeak')
# 选择英文语音(二选一,均来自你 espeak --voices 列表)
# 选项1:英式英语(en-gb,推荐,发音更清晰)
engine.setProperty('voice', 'en-gb')
# 选项2:美式英语(en-us,若偏好美式发音可切换)
# engine.setProperty('voice', 'en-us')
# 优化语音参数(适配树莓派)
engine.setProperty('rate', 140) # 语速(120-150为宜,避免过快)
engine.setProperty('volume', 0.8) # 音量(0.0-1.0,避免过小)
# -------------------------- 2. 人脸检测基础配置 --------------------------
# 加载训练好的人脸模型(确保 trainer.yml 路径正确)
recognizer = cv2.face.LBPHFaceRecognizer_create()
# 若报错"trainer/trainer.yml not found",先创建文件夹:mkdir -p trainer
recognizer.read('trainer/trainer.yml')
# 加载人脸检测分类器(树莓派默认路径,避免文件缺失)
cascadePath = "/usr/share/opencv4/haarcascades/haarcascade_frontalface_default.xml"
faceCascade = cv2.CascadeClassifier(cascadePath)
# 配置显示字体
font = cv2.FONT_HERSHEY_SIMPLEX
id = 0 # 初始化识别ID
# 已注册用户列表(英文名称,与训练模型的ID对应)
# 注意:顺序需和你训练人脸时的用户ID一致(如ID=1对应Marcelo)
names = ['Unknown', 'Marcelo', 'Paula', 'Ilza', 'Zack', 'Will']
# -------------------------- 3. 防重复播报机制(避免循环中频繁播报) --------------------------
last_recognized = "Unknown" # 上一次识别结果
speak_cooldown = 30 # 冷却时间(单位:帧,树莓派1秒≈30帧,即1秒内只播报1次)
cooldown_counter = 0 # 冷却计数器
# -------------------------- 4. 初始化摄像头 --------------------------
# 树莓派USB摄像头用0,CSI摄像头用1(根据实际硬件调整)
cam = cv2.VideoCapture(0)
cam.set(3, 640) # 摄像头宽度
cam.set(4, 480) # 摄像头高度
# 最小人脸尺寸(避免检测过小的无效区域)
minW = 0.1 * cam.get(3)
minH = 0.1 * cam.get(4)
# -------------------------- 5. 主循环(人脸检测+英文语音播报) --------------------------
print("Face Recognition Started. Press ESC to exit.")
while True:
ret, img = cam.read()
if not ret: # 防止摄像头未连接导致崩溃
print("Error: Could not read frame from camera.")
break
# 翻转画面(确保显示方向正确,可根据实际情况调整)
img = cv2.flip(img, -1)
# 转为灰度图(人脸检测需灰度图,降低计算量)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测画面中的人脸
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.2, # 检测缩放因子(避免漏检)
minNeighbors=5, # 最小邻域数(过滤误检)
minSize=(int(minW), int(minH)) # 最小人脸尺寸
)
# 冷却计数器递减(每帧减1,直到0)
if cooldown_counter > 0:
cooldown_counter -= 1
# 处理每个检测到的人脸
for (x, y, w, h) in faces:
# 绘制人脸框(绿色,线宽2)
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 识别人脸(返回ID和置信度,置信度越低匹配越准)
id, confidence = recognizer.predict(gray[y:y + h, x:x + w])
# 判断识别结果:置信度<100为已注册用户,否则为陌生人
if confidence < 100:
recognized_name = names[id]
# 计算匹配准确率(100 - 置信度)
confidence_text = f" {round(100 - confidence)}% Match"
else:
recognized_name = "Unknown" # 未注册用户(陌生人)
confidence_text = f" {round(100 - confidence)}% Match"
# -------------------------- 英文语音播报(冷却期外+结果变化时触发) --------------------------
if cooldown_counter == 0 and recognized_name != last_recognized:
if recognized_name == "Unknown":
engine.say("Warning: Unknown person detected") # 陌生人播报
else:
engine.say(f"Welcome, {recognized_name}") # 已注册用户播报
engine.runAndWait() # 执行播报
last_recognized = recognized_name # 更新上一次识别结果
cooldown_counter = speak_cooldown # 启动冷却,避免重复播报
# 在画面上显示识别结果(姓名和准确率)
cv2.putText(img, recognized_name, (x + 5, y - 5), font, 1, (255, 255, 255), 2)
cv2.putText(img, confidence_text, (x + 5, y + h - 5), font, 1, (255, 255, 0), 1)
# 显示实时画面
cv2.imshow('Face Recognition Camera', img)
# 按ESC键退出(等待10ms刷新画面)
k = cv2.waitKey(10) & 0xff
if k == 27:
break
# -------------------------- 6. 释放资源(避免内存泄漏) --------------------------
print("\n[INFO] Exiting program. Releasing resources...")
cam.release() # 释放摄像头
cv2.destroyAllWindows() # 关闭所有窗口
engine.stop() # 停止语音引擎